Logging and Monitoring for Amazon SP-API Applications
Implement logging and monitoring requirements for Amazon Selling Partner API applications.
Comprehensive logging and monitoring practices are essential for protecting Amazon Selling Partner API applications from security threats and operational issues. This guide outlines logging and monitoring requirements that align with the Amazon Data Protection Policy (DPP) and Acceptable Use Policy (AUP). Solution providers must implement these requirements to create secure environments that minimize data loss risks and protect sensitive information.
Logging and monitoring requirements
Solution providers must follow a structured approach to implement the following logging and monitoring requirements:
- Prerequisites
- Log requirements
- Incident Response Plan requirements
- Log protection and backup systems
- Monitoring and verification controls
- Ongoing maintenance and documentation
- AWS implementation
Prerequisites
Before implementing logging and monitoring mechanisms, solution providers must:
- Evaluate their current logging and monitoring capabilities.
- Identify gaps against Amazon Data Protection Policy (DPP) requirements.
- Develop a detailed implementation plan that includes a project timeline and key milestones.
Amazon Data Protection Policy (DPP) requirements
To comply with the Logging and Monitoring requirements in the DPP, solution providers must:
- Gather logs to detect security-related events to their applications and systems.
- Implement logging mechanisms on all channels that provide access to information.
- Review logs in real-time or on a bi-weekly basis.
- Establish access controls to prevent any unauthorized access and tampering.
- Ensure that logs do not contain PII unless the PII is necessary to meet legal requirements, including tax or regulatory requirements.
- Retain logs for at least 12 months.
- Build mechanisms to monitor the logs and all system activities to trigger investigative alarms on suspicious actions.
- Detect when information is extracted from or found beyond its protected boundaries.
- Designate an Incident Management Point of Contact (IMPOC) and create an Incident Response Plan.
Log requirements
Solution providers must maintain comprehensive log data to enable effective forensic investigations and root cause analysis. To implement comprehensive logging and monitoring, solution providers must identify system components that require logs, document essential elements such as system parameters and API calls, and establish mechanisms to detect security-related events across all applications and systems.
Understanding logs and their role in security
Logs are digital records of events occurring within an organization's systems and networks. Each log entry contains information about a specific event, providing a chronological account of system activities. While initially used for troubleshooting, logs now serve multiple critical functions:
- Detecting security incidents and policy violations.
- Identifying fraudulent activities and operational issues.
- Supporting forensic analysis and internal investigations.
- Establishing performance baselines and tracking trends.
Important
Solution providers should exercise caution regarding log integrity from potentially compromised systems. Insecure log sources may be susceptible to tampering or manipulation.
Log entry elements
Each log entry must include:
- Date and time stamps.
- Source and destination addresses.
- User or process identifiers.
- Event descriptions.
- Success or failure indications.
- Filenames involved.
- Access control or flow control rules invoked.
- Origination of event.
- Identity or name of affected data, system component, or resource.
Log event types
Solution providers must log the following types of events:
- Access and authorization attempts.
- Configuration changes.
- Intrusion attempts.
- Data changes.
- System errors.
- Account management events.
- Process tracking.
- System events/errors.
- Authentication/authorization checks.
- API requests to service endpoints and administrative dashboards.
Important
Logs must not contain Personally Identifiable Information (PII) unless necessary to meet legal requirements, including tax or regulatory requirements.
Log management infrastructure and design considerations
Solution providers must build, design, and implement log management systems that can:
- Collect and store logs in a centralized place.
- Protect log data integrity from modification or deletion.
- Maintain log data confidentiality.
- Handle expected log volumes, including during peak situations like security incidents or testing.
- Analyze logs across the organization.
To ensure that their log management system continues to meet organizational needs, solution providers must conduct regular reviews.
Log implementation
Solution providers must:
- Implement logging mechanisms on all channels that provide access to information, including:
- Service APIs.
- Storage-layer APIs.
- Administrative dashboards.
- Ensure logs capture all customer-facing actions.
- Record all internal and external API calls.
- Maintain audit trails for all system components.
Log review and retention
Solution providers must:
- Review logs in real-time using a Security Information and Event Management (SIEM) tool, or at minimum, on a bi-weekly basis.
- Implement access controls to prevent unauthorized access and tampering throughout the log lifecycle.
- Store logs centrally and securely.
- Retain logs for at least 12 months for reference in case of a security incident.
- Synchronize time and date configurations to maintain log consistency across the infrastructure.
- Define and document procedures for:
- Accessing logs from different service components.
- Reviewing log content and identifying anomalies.
- Offloading logs for analysis or archival.
- Managing log rotation and cleanup.
Incident Response Plan requirements
Solution providers must maintain clear incident response procedures by establishing:
- Designated points of contact.
- Investigation protocols.
- Documentation requirements.
- Response plan maintenance.
Incident Management Point of Contact (IMPOC) role and procedures
Solution providers must designate and maintain an Incident Management Point of Contact (IMPOC) as part of their logging and monitoring infrastructure. The IMPOC serves as the primary coordinator for security events and incident response activities.
Best practices:
- Be available 24/7 for critical security incidents.
- Have access to necessary systems and resources for incident investigation.
- Have authority to initiate incident response procedures.
- Maintain direct communication channels with Amazon security team.
The IMPOC is responsible for:
- Coordinating initial incident response activities.
- Managing communication with Amazon security team.
- Ensuring proper documentation of security events.
- Overseeing incident investigation and remediation.
- Maintaining incident response documentation.
- Coordinating regular incident response drills.
The IMPOC must establish and maintain the following communication protocols:
- Primary and backup communication channels
- Escalation procedures for different severity levels
- Regular status update mechanisms
- Documentation requirements for incident communication
- Procedures for engaging third-party resources when needed
Team enablement
Solution providers must support their IMPOCs and monitoring teams through:
- Tool training and documentation.
- Technical guidance.
- Regular knowledge updates.
- Implementation support.
By establishing robust monitoring systems, solution providers can detect and respond to potential security threats before they impact data security.
Log protection and backup systems
Solution providers must implement comprehensive protection for logging facilities and log information to prevent tampering and unauthorized access. This section outlines required controls for securing log data throughout its lifecycle.
Access control requirements
- Restrict access based on job function and need-to-know basis.
- Implement physical and network segregation controls.
- Maintain active audit trails across system components.
- Prevent unauthorized modifications to log data.
Storage and recovery systems
- Centralize log storage on secure internal servers.
- Maintain geographically separated backup sites for redundancy.
- Ensure storage media integrity through tamper-resistant controls.
- Implement backup procedures for:
- Audit trail files.
- External-facing system logs (firewalls, DNS, mail).
- Critical system components.
- Establish recovery procedures for both physical and technical incidents.
Monitoring and verification controls
To create a robust security program, solution providers must set up effective monitoring and alerting systems.
Real-time monitoring
- Monitor across critical system components, such as:
- Security tools
- Identity systems
- Operating systems
- Applications
- Deploy file integrity monitoring and change detection systems.
- Review security logs daily and address exceptions.
- Conduct regular system-wide log reviews.
- Review auditable events annually or when significant system changes occur.
Alert threshold configurations
Configure monitoring systems to detect anomalous activities, such as:
- Unusual access patterns or data retrieval.
- System and service failures.
- Potential data exposure.
- Performance anomalies.
Define and implement specific thresholds for:
-
Authentication and Access:
- User accounts must be locked out after 10 or fewer unsuccessful login attempts
- Privileged account access: Alert on all access attempts
- Off-hours access: Alert on access outside business hours
- Geographic anomalies: Alert on access from unexpected locations
-
Data Access and Movement
- Large data transfers: Alert on transfers exceeding defined thresholds
- Sensitive data access: Real-time alerts for PII access
- Unusual access patterns: Alert on deviation from baseline
- API call volume: Alert on unexpected spikes
-
System Changes
- Configuration changes: Alert on all production changes
- Security control modifications: Immediate alerts
- System resource utilization: Alert on threshold exceeded
- Service availability: Alert on degradation or failure
Dark Web monitoring
To detect if information is leaked or found beyond its protected boundaries, such as the Dark Web, establish monitoring practices and document incidents in the incident response plan.
Implement continuous monitoring for:
- Exposed credentials and access keys.
- Leaked customer data.
- Compromised system information.
- Malicious actor discussions about your systems.
Configure the following automated responses:
- Lock out accounts after threshold violations
- Block IPs for suspicious activity
- Terminate sessions that violate policies
- Isolate compromised systems
Ongoing maintenance and documentation
Solution providers must establish procedures that review and verify the plan every six months and after any major infrastructure or system change. Solution providers must also manage a risk assessment and management process that senior management reviews annually.
Solution providers must also maintain documentation that demonstrates the following:
- Regular testing of monitoring systems
- Validation of alert thresholds
- Verification of response procedures
- Assessment of IMPOC effectiveness
- Dark Web monitoring results
- Incident response drill outcomes
AWS implementation
AWS provides several services and tools to help solution providers implement comprehensive logging and monitoring solutions. The following sections describe two key implementations: CloudWatch for real-time monitoring and alerting, and OpenSearch Service for centralized logging and analysis.
Amazon CloudWatch alarms for notifications
When developing, deploying, and supporting business-critical applications, timely system notifications are crucial to keep services up and running reliably. For example, a team who actively collaborates using Amazon Chime or Slack might want to receive critical system notifications directly within team chat rooms. This is possible using Amazon Simple Notification Service (SNS) with AWS Lambda.
Amazon CloudWatch alarms enable setting up metric thresholds and sending alerts to Amazon SNS. Amazon SNS can send notifications using e-mail, HTTP(S) endpoints, and Short Message Service (SMS) messages to mobile phones. Amazon SNS can even initiate a Lambda function.
Amazon SNS doesn’t currently support sending messages directly to Amazon Chime chat rooms, but a Lambda function can be inserted between them. By initiating a Lambda function from Amazon SNS, the event data can be consumed from the CloudWatch alarm and a human friendly message can be crafted before sending it to Amazon Chime or Slack.
The following architectural diagram demonstrates how the various components work together to create this solution.
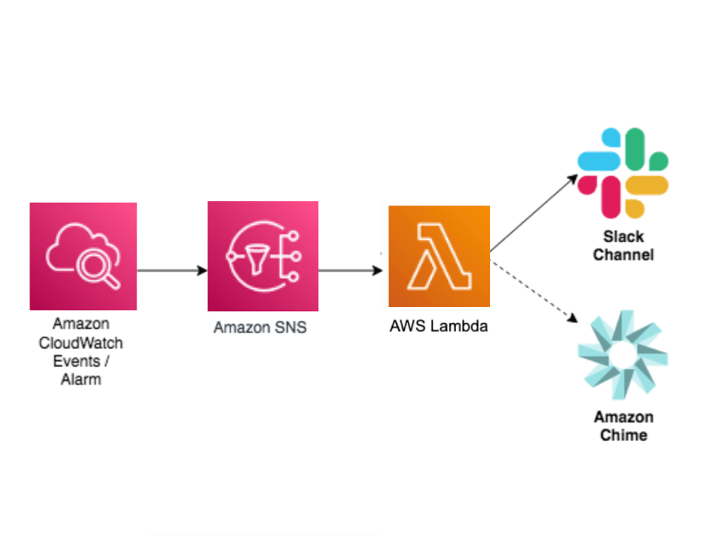
For more information, refer to the AWS Knowledge Center.
Centralized logging with Amazon OpenSearch Service
This section discusses the AWS solution for log ingestion, log processing, and log visualization. This centralized logging solution uses Amazon OpenSearch Service which includes a dashboard visualization tool, OpenSearch Dashboards, that helps visualize not only log and trace data, but also machine-learning powered results for anomaly detection and search relevance ranking.
From an operational and security perspective, API call logging provides the data and context required to analyze user behavior and understand certain events. API call and IT resource change logs can also be used to demonstrate that only authorized users have performed a certain task in an environment in alignment with compliance requirements. However, given the volume and variability associated with logs from different systems, it can be challenging in an on-premise environment to gain a clear understanding of the activities users have performed and the changes made to IT resources.
AWS provides the centralized logging solution to enable organizations to collect, analyze, and display Amazon CloudWatch Logs in a single dashboard. This centralized logging solution uses Amazon OpenSearch Service with the dashboard visualization tool OpenSearch Dashboards. This solution provides a single web console to ingest both application logs and AWS service logs in to the Amazon OpenSearch Service domains.
OpenSearch Dashboards helps visualize not only log and trace data, but also machine-learning powered results for anomaly detection and search relevance ranking. In combination with other AWS managed services, this solution provides capabilities of centralized log ingestion across multiple regions and accounts, one-click creation of codeless end-to-end log processors, and templated dashboards for visualization to customers, complementary of Amazon OpenSearch Service.
You can deploy a centralized logging architecture automatically on AWS. For more information, refer to Centralized Logging on AWS. For more information on logging best practices in AWS, refer to the Introduction to AWS Security.
Key takeaways and next steps
- Implement comprehensive logging and monitoring controls as outlined in this document to comply with Amazon's Data Protection Policy.
- Establish real-time monitoring and alerting systems that can detect and respond to security threats promptly.
- Regularly review your logging implementation against the Data Protection Policy requirements to ensure continued compliance.
Additional resources
For additional information, refer to:
Notices
Amazon sellers and developers are responsible for making their own independent assessment of the information in this document. This document: (a) is for informational purposes only, (b) represents current practices, which are subject to change without notice, and (c) does not create any commitments or assurances from Amazon.com Services LLC (Amazon) and its affiliates, suppliers or licensors. Amazon Services API products or services are provided “as is” without warranties, representations, or conditions of any kind, whether express or implied. This document is not part of, nor does it modify, any agreement between Amazon and any party.
Updated 25 days ago